
Japan.R 2013でコイン投げの分析を一捻りと題して発表してきました。ノンパラメトリックな手法を学習しているうちに見つけたのでご紹介いたしました。
2013年12月17日火曜日
2013年12月9日月曜日
TopCoder SRM482 Div2 275Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
public class AverageAverage {
public double average(int[] numList) {
double val = 0.0;
for( int i=0 ; i<numList.length ; i++ ){
val += numList[i];
}
return val/numList.length;
}
}
得点は273.16/250、1回のsubmitでシステムテストクリア。 (問題文の翻訳を誤って消してしまいました...numListから1つ以上の要素を取り出すパターンを列挙し、各パターンで平均を求め、その平均を求めよという問題だったと思います。)
2013年11月20日水曜日
TopCoder SRM481 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
あなたは円の形に配置された多くの店からなるマーケットを訪れている。店は0からn-1という番号が時計回りにつけられている。各お店からちょうど一つずつの品物を買いたいと思っている。そこでお店0を時刻0秒で出て、時計回りにお店を回る。もしお店iにopenTime[i]より前、もしくはcloseTime[i]より後に到着したら、それはお店は閉まっており、購入を行えないことを意味する。もしopenTime[i]とcloseTime[i]の間に到着し、かつまだそのお店でほしいものを購入していないのであれば、即座にそれを買わなければならない(購入に時間はかからないものとする)。どちらの場合においても、すぐに次の店に向かわなければならない。2つのお店の間を移動するのにはtravelTime秒かかる。もし何も購入できなくなったらマーケットを離れるものとする。購入可能なものの合計数を返せ。
public class CircleMarket {
public int makePurchases(int[] openTime, int[] closeTime, int travelTime) {
boolean[] passedClosedTime = new boolean [openTime.length];
boolean[] alreadyPurchase = new boolean [openTime.length];
int currentTime = 0;
int nPurchase = 0;
int i = 0;
while( true ){
if( isAllClosed(passedClosedTime) ) break;
if( openTime[i] <= currentTime && currentTime <= closeTime[i] ){
if( alreadyPurchase[i] == false ){ // お店は開店中でまだ購入済みでない
nPurchase++; // 購入数をカウントアップ
alreadyPurchase[i] = true; // 購入済みフラグを立てる
}
}else if( currentTime > closeTime[i] ){ // 閉店時刻を過ぎていた
passedClosedTime[i] = true; // 閉店済みフラグを立てる
}
i++;
i %= openTime.length; // 次のお店への移動
currentTime += travelTime; // 次のお店に進んだ時へ時刻をすすめる
}
return nPurchase;
}
private boolean isAllClosed(boolean[] state){ // すべてのお店が閉まっているかを判断するメソッド
for( int i=0 ; i<.length ; i++ ){
if( state[i] == false ) return false;
}
return true;
}
}
得点は217.27/250、1回のsubmitでシステムテストクリア。時間と既に買ったかを管理する論理値型配列、現在時刻、購入したものの数、訪問しているお店の番号を組み合わせて実装。
TopCoder SRM480 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
TopCoder Security Agency(TSA、本日設立された)は今新しい暗号化システムを開発した。この暗号化システムは暗号化する数字の列を入力として受け取る。あなたはTSAで働いており、仕事は暗号化プロセスの重要な部分を実装することである。入力のなかから1つの数字を取り出し、その値を1増やすことが認められている。これはリスト中のすべての数字の積ができるだけ大きくなるように行われなければならない。numbers[]という数字の列が与えられたとき、得られる積の最大値を返せ。ただし、返される値は2^62を超えないことは保証されているものとする。
import java.util.Arrays;
public class Cryptography {
public long encrypt(int[] numbers) {
Arrays.sort(numbers);
long n = numbers[0] + 1;
for( int i=1 ; i<numbers.length ; i++ ){
n *= numbers[i];
}
return n;
}
}
得点は247.04/250、1回のsubmitでシステムテストクリア。積を最大化するということは、最小値を見つけてそれに1を加えればよいということに気づけばOK。
2013年11月17日日曜日
TopCoder SRM479 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ジョンとブラスは飛行機を所有している。彼らはいくつかの連続したフライトをしようとしている、flightsのi番目の要素はi番目のフライトに必要な燃料を表している。フライトはflightsにある順序で行われる。最初にfuelリットルの燃料が飛行機にある。フライトを行うためには、飛行機の燃料が少なくともそのフライトに必要な量がなければならない。燃料を再度入れることなくフライトをこなせる回数の最大値を返せ。
public class TheAirTripDivTwo {
public int find(int[] flights, int fuel) {
int total = 0;
for( int i=0 ; i<flights.length ; i++ ){
total += flights[i];
if( total > fuel ) return i;
}
return flights.length;
}
}
得点は247.96/250、1回のsubmitでシステムテストクリア。順番にチェックしていくだけ。
2013年10月28日月曜日
TopCoder SRM478 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
タロウはおいしいキウイフルーツのジュースを用意した。彼はそれを0からN-1までの数字がつけられたN個のボトルに注いだ。i番目のボトルの容量はcapacities[i]リットルであり、bottees[i]リットルをそのボトルに注いでいる。そして、彼はボトルのジュースを再分配したいと思っている。このために0からM-1まで番号を付けられた操作を行う。i番目の捜査ではfromId[i]からtoId[i]にジュースを注ぐ。注ぐのをやめるのはfromId[i]の中が空になるか、toId[i]の容量が満杯になるかのどちらか早い方である。すべての操作が終わった時のキウイジュースの量を表したN個の要素からなる整数型の配列を返せ。
public class KiwiJuiceEasy {
public int[] thePouring(int[] capacities, int[] bottles, int[] fromId, int[] toId) {
for( int i=0 ; i<fromId.length ; i++ ){
int from = bottles[fromId[i]]; // 注げる量
int to = bottles[toId[i]];
int toLeft = capacities[toId[i]] - to; // 注げる量
int pourAmount = Math.min(from, toLeft); // 小さい方を調べて
bottles[fromId[i]] -= pourAmount; // 移し替える操作
bottles[toId[i]] += pourAmount;
}
return bottles;
}
}
得点は242.44/250、1回のsubmitでシステムテストクリア。
2013年10月23日水曜日
TopCoder SRM477 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
N日(1~Nという日とする)のうちK日(1<=K<=N)連続した休みがとりたいのだが、workingDaysにある日については会議がある(配列の要素は1以上N以下の整数で与えられる)。このとき会議がある日を最小でいくつずらせば、K日の連続した休みを取ることができるか。
import java.util.Arrays;
public class VacationTime {
public int bestSchedule(int N, int K, int[] workingDays) {
Arrays.sort(workingDays);
int mindays = workingDays.length + 1;
for( int i=1 ; i<=N-K+1 ; i++ ){
int ndays = 0;
for( int j=i ; j<i+K ; j++ ){
for( int k=0 ; k<workingDays.length ; k++ ){
if( workingDays[k] == j ) ndays++;
}
}
if( ndays < mindays ) mindays = ndays;
}
return mindays;
}
}
得点は190.81/250、1回のsubmitでシステムテストクリア。本文はもうちょっと前フリがあるのですが、面倒なので省略。
2013年10月20日日曜日
TopCoder SRM476 Div2 300Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
N×Mの数字で埋められた行列がある。行列の要素は0~9である。この行列に対し、4つの操作が定義されている。それらは1行上にシフト(1番上の行は1番下に移動)、1行下にシフト(1番下の行は1番上に移動)、1列左にシフト(1番左の行は1番右に移動)、1列右にシフト(1番右の行は1番左に移動)というものである。1行しかなければ、1行上、下にシフトする操作は意味をもたないし、同様に、1列しかなければ1列左、右にシフトする操作は何も効果がないことに注意。matrix[]という、i番目の文字列のj番目の要素が行列の(i, j)要素を表す文字列型配列が与えられたとき、valueという値が一番左上に移動するのに必要な操作の回数の最小値を返せ。なお、valueに該当する値はmatrix中に複数存在することがある。左上に動かすべき要素がないときには-1を返せ。
public class MatrixShiftings {
public int minimumShifts(String[] matrix, int value) {
int nRow = matrix.length;
int nCol = matrix[0].length();
int minMove = nRow + nCol; // 最小移動回数のカウント
int[][] array = new int[nRow][nCol]; // とりあえず数値として扱うことにする
for( int i=0 ; i<nRow ; i++ ){
char[] line = matrix[i].toCharArray();
for( int j=0 ; j<nCol ; j++ ){
array[i][j] = line[j] - '0';
}
}
if( isExist(array, value) == false ) return -1; // 1個も検討すべき値がなければ-1で終了
for( int i=0 ; i<nRow; i++ ){
for( int j=0 ; j<nCol ; j++ ){
if( array[i][j] == value ){
int moveRow = Math.min(i, nRow-i); // 行方向に動かすべき最小回数
int moveCol = Math.min(j, nCol-j); // 列方向に動かすべき最小回数
minMove = Math.min(minMove, moveRow+moveCol); // valueが左上のセルに移動するまでの最小の移動回数を更新
}
}
}
return minMove;
}
private boolean isExist(int[][] a, int value){
for( int i=0; i<a.length; i++ ){
for( int j=0; j<a[0].length; j++ ){
if( a[i][j] == value ) return true;
}
}
return false;
}
}
得点は254.13/300、1回のsubmitでシステムテストクリア。位置だけで左上のセルへの最小移動回数は決まるので、valueに合致するすべてのセルについてその回数を計算するだけ。コードは長いが、250点でも良さげ。
2013年10月17日木曜日
TopCoder SRM475 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ウサギたちはしばしばさびしさを感じるので、あるグループがまとまり、どれが一番美しい耳かを競うビューティーコンテストを開催した。1匹が1票を持つ。もし自身に投票した場合は無効となる。もっとも票数が多かったのが勝者となる。namesがウサギの名前、votesが投票先、それぞれのi番目の要素について取り出すと、ウサギnames[i]がvotes[i]に投票したということを意味する。勝者を文字列で返せ。もし複数の勝者がいるのであれば、空文字を返せ。
私の解答はこちら。
import java.util.HashMap;
public class RabbitVoting {
public String getWinner(String[] names, String[] votes) {
HashMap<String, Integer> hm = new HashMap<String, Integer>();
for( int i=0 ; i<names.length ; i++ ){
if( names[i].equals(votes[i]) ) continue; // 自分に投票したら票として扱わない
if( hm.containsKey(votes[i]) ){ // 票としてカウント
hm.put(votes[i], hm.get(votes[i])+1 );
}else{
hm.put(votes[i], 1);
}
}
int maxvotes = -1;
String winner = "";
for( String key: hm.keySet() ){ // こういうループもある
if( maxvotes < hm.get(key) ){ // 最多得票数を更新した場合
winner = key;
maxvotes = hm.get(key);
}else if( maxvotes == hm.get(key) ){ // 最多得票数が複数でた場合
winner = "";
}
}
return winner;
}
}
得点は189.29/250、2回目のsubmitでシステムテストクリア。最初にputするときに0で初期化して間違えるというオチ(1で初期化する必要がある)。
2013年10月16日水曜日
TopCoder SRM474 Div2 250Pts
今回解いた問題は、文字列Aの途中(Aの先頭と最後尾も含む)のすべての位置に文字列Bを挟んだとき、できた文字列が回文になっている数を返すメソッドを作成せよという問題。
私の解答はこちら。
public class PalindromesCount {
public int count(String A, String B) {
int n = 0;
for( int i=0 ; i<=A.length() ; i++ ){ // 最後尾に付け足すので、A.lengthまで調べる必要がある
String cur = A.substring(0, i) + B + A.substring(i); // Aの途中にBを挟んだ文字列を生成
if( isPalindrome(cur) ) n++;
}
return n;
}
private boolean isPalindrome(String s){ // 文字列をひっくり返して一致しているか調べる
StringBuffer sb = new StringBuffer(s);
String rev = sb.reverse().toString();
return s.equals(rev);
}
}
得点は240.30/250、1回のsubmitでシステムテストクリア。割ときれいにかけました。
2013年10月7日月曜日
2013年9月の学習記録
- とある弁当屋の統計技師(pp.1~読了)
- 初心者向けには良いと思う。高校1年生向けかと言われると後半はちょっと怪しい気がしないでもない。
- サンプルサイズの決め方(pp.61~70)
- t検定で一定の検定力を持つために必要なサンプル数について学ぶ。うーん、ちょっと理論が飛躍している箇所があるぞ...
その他、データサイエンティスト完全ガイドを半分ほど読むなど。
2013年9月21日土曜日
2013年8月の学習記録
外出が多すぎて大したことができておりませぬ...
- サンプルサイズの決め方(pp.16~60)
- 相変わらずのマニアック感。
- オープンソース・ソフトウェアルータVyatta入門(pp.1~74)
- ルータ、NAT変換、ファイアウォール、DNSやNTPのサーバを指定する設定など。機能を分割して複数のマシンでメールサーバを構築してました。
その他、TopCoderの易問をいくつか解くなど。
2013年9月4日水曜日
TopCoder SRM473 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
頭の数をhead、脚の数をlegsとするとき、鶴亀算を行い、鶴の数と亀の数を表す要素2の整数型の配列を返せ。もし適切な解がない場合は要素数0の整数型の配列を返せ。
私の解答はこちら。
public class OnTheFarmDivTwo {
public int[] animals(int heads, int legs) {
if( 4*heads - legs < 0 || legs - 2*heads < 0 ){
int[] x= new int[0];
return x;
}
if( (4*heads - legs) % 2 != 0 || (legs - 2*heads) % 2 != 0 ){
int[] x= new int[0];
return x;
}
int[] x = {(4*heads - legs)/2, (legs - 2*heads)/2};
return x;
}
}
得点は233.91/250、1回のsubmitでシステムテストクリア。連立方程式を立てて解が非負の整数になるような条件を求める方針で解きました。日本語訳なので鶴亀算と紹介しましたが、英文では鶴を鶏と亀を牛で表現していました。そこは興味深いところかもしれません。
2013年9月3日火曜日
TopCoder SRM472 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
タロウはカラフルなもの、特にカラフルなタイルが好きである。タロウの部屋は連続したL個のタイルで区切られている。各タイルは以下の4つの色の1つである:赤、緑、青、黄。roomという文字列が与えられ、各部屋のi番目の文字はR、G、BまたはYで現され、それぞれ赤、緑、青、黄を表している。タロウは隣り合う部屋の色が同じにならないように部屋の色を変えることにした。変えなければならないタイルの数の最小値を返せ。
私の解答はこちら。
public class ColorfulTilesEasy {
public int theMin(String room) {
int nChange = 0;
char[] roomchars = room.toCharArray();
char prevColor = 'X';
for( int i=0 ; i<room.length() ; i++ ){
char curColor = room.charAt(i);
if( curColor == prevColor ){
nChange++;
roomchars[i] = 'X';
}
prevColor = roomchars[i];
}
return nChange;
}
}
得点は243.22/250、1回のsubmitでシステムテストクリア。1文字ごとに分解してしまえばしめたものです。
2013年8月4日日曜日
2013年7月の学習記録
7月後半はNagoya.R #10の準備が結構なウェイトを占めておりました。
- CentOS 6で作るネットワークサーバ構築ガイド(14章の辺り)
- mailing listサーバ構築などで参照。仮想メールサーバ(postfix+dovecot+mysql+postfixadmin)を練習で構築したのですが、quota機能をつけてpostfixを再コンパイルするといった内容は、テキストに載っていないので、扱っていることの程度は相当上がってきたように思われます。
- ノンパラメトリック統計入門(pp.211〜読了)
- KS検定、スミルノフ検定や順位相関など。この辺りは有意となるための限界値の導出根拠が不足していて若干消化不良気味。統計のテキストは結構気になることを省いているので、証明を省くのであれば、せめて証明の載っている参考書や論文ぐらいは提示してほしいなとは思います。特に省かれているなという印象を持つのは、独立性の検定の自由度に関する説明、モーメント母関数と確率密度関数の1-1対応の理由辺りでしょうか。難しいと言い切らず、書いておいてほしいよ~
- 確率化テストの方法(pp.1~32)
- ノンパラ関連でちょっとだけ目を通す。独特な本という印象。
- サンプルサイズの決め方(pp.1~15)
- この手の話を日本語で読める貴重な本のように思います。例えば、帰無仮説を受容する際に、積極的に帰無仮説であると言い切るためには、帰無仮説からちょいと離れた位置での検出力が十分高ければOKと考えればよいとか書いてあります。普通の学部向けテキストでこういう書き方をしているものはこれまで見たことがありませんでした。次の読破目標の統計本はこれ。
その他、「統計学が最強の学問である」を読了したほか、TopCoderの易問をいくつか解くなど。
2013年7月31日水曜日
TopCoder SRM471 Div2 250Pts
このTopCoderの問題は検索にかけても現れないのですが、簡単に説明してみます。
エリーは"2で割る"問題が大好きである。これにより彼女は2で割らなければならない問題を意味している。エリーはそれ自身が素数を含む数があることに気づいた。数XがYという数字を持つというのは、Y=X/2^k(非負の整数kで割って、切り捨てられたもの)を満たしているときをいう。エリーはすべての正の整数を"prime container"と呼び、その数が含む素数の数をprime containerの大きさと定義した。例えば、7の大きさは2である。これは7/1=7、7/2=3がともに素数だからである(訳注:これを続けると7/2^2=1なので素数にならない)。同様に47は5、959は6が得られる。正の整数Nが与えられたとき、その数のprime containerの大きさを求めることでエレノラを手伝え。
私の解答はこちら。
public class PrimeContainers {
public int containerSize(int N) {
int ans = 0;
for( int i=1 ; i<=N ; i=i*2 ){
int target = N / i;
if( isPrime(target) && target >= 2 ){
ans++;
}
}
return ans;
}
boolean isPrime(int n){ // 素数か判定するプログラム
int end = (int)Math.sqrt(n);
for( int i=2 ; i<=end ; i++ ){
if( n % i == 0 ) return false;
}
return true;
}
}
得点は218.65/250、1回のsubmitでシステムテストクリア。後半の英文の意味が拾いにくかったので、意訳してしまいました。
2013年7月30日火曜日
Rでノンパラメトリック法 1
Nagoya.R #10にて、「Rでノンパラメトリック法 1」と題して発表してきました。1冊の本が終わるか私が納得するまでシリーズとして続ける予定なので、2回目以降もきっとあるはずということで1とスライドの題名につけました。今回はノンパラメトリックな手法として符号検定とウィルコクソンの符号付き順位和検定を取り上げています。手計算とRでの実行結果が一致することを確認しながら、理屈を知ろうという内容になっております。
Rでノンパラメトリック法 1 from itoyan110
2013年7月17日水曜日
TopCoder SRM470 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
巡回しているセールスマンはLinear王国で製品を売ろうとしている。Linear王国は座標系にNの街がある。各街は点であり、i番目の街は(x[i], y[i])にある。Linear王国のすべての街は共線性がある、すなわちすべての街を通るまっすぐの線が存在することを意味する。巡回セールスマンはすべての街を訪問しようとしている。2つの街を移動するのに必要な距離はマンハッタン距離に等しい。任意の街から移動し、任意の街で移動を終えるとしたとき、セールスマンが移動しなければならない距離の最小値を返せ。
私の解答はこちら。
public class LinearTravellingSalesman {
public int findMinimumDistance(int[] x, int[] y) {
int[] minDist = {0, 0};
boolean isStart = true;
int[] prev = {0, 0};
boolean[] isUsed = new boolean[x.length];
for( int i=0 ; i<x.length ; i++ ){
int target = -1;
int minx = 10001;
for( int j=0 ; j<x.length ; j++ ){
if( isUsed[j] == false && x[j] < minx ){
target = j;
minx = x[j];
}
}
if( !isStart ){
minDist[0] += ( Math.abs(x[target] - prev[0]) + Math.abs(y[target] - prev[1]));
}
prev[0] = x[target];
prev[1] = y[target];
isStart = false;
isUsed[target] = true;
}
for( int i=0 ; i<x.length ; i++ ){
isUsed[i] = false;
isStart = true;
}
prev[0] = 0; prev[1] = 0;
for( int i=0 ; i<x.length ; i++ ){
int target = -1;
int minx = 10001;
for( int j=0 ; j<x.length ; j++ ){
if( isUsed[j] == false && y[j] < minx ){
target = j;
minx = y[j];
}
}
if( !isStart ){
minDist[1] += ( Math.abs(x[target] - prev[0]) + Math.abs(y[target] - prev[1]));
}
prev[0] = x[target];
prev[1] = y[target];
isStart = false;
isUsed[target] = true;
}
return minDist[0] < minDist[1] ? minDist[0] : minDist[1];
}
}
得点は183.36/250、1回のsubmitでシステムテストクリア。PCが壊れる前に解き、コメントがないので解き方の方針は忘れてしまいました(苦笑)
2013年7月7日日曜日
TopCoder SRM469 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ジョンとブラスはとても面白い映画を見に行こうとしている。彼らは同じ並びの隣り合った席に座りたいと思っている。映画館はn行m列のシートからなる。行方向は先頭から最後尾へ向けて1からnと番号づけられ、左から右に1からmと順に番号づけられている。いくつかのシートは既に埋まっており、ジョンとブラスは任意の空いている席を予約することができる。row、seatという整数型の配列が与えられ、そのi番目の要素row[i]、seat[i]は予約された席の位置を示している。すべての残りの席は空いている。ジョンとブラスが同じ並びで隣り合って座ることができる場合の数を返せ。なお、ジョンとブラスの位置までは考慮しないものとする。つまりジョンとブラスが逆に座っても同じ席の予約なので1通りとしてカウントするということである。
私の解答はこちら。
public class TheMoviesLevelOneDivTwo {
public int find(int n, int m, int[] row, int[] seat) {
boolean[][] isReserved = new boolean[n][m];
for( int i=0 ; i<row.length ; i++ ){
isReserved[row[i]-1][seat[i]-1] = true;
}
int nSeat = 0;
boolean isPrevReserved = true;
int nFree = 0;
for( int i=0 ; i<n ; i++ ){
nFree = 0;
isPrevReserved = true;
for( int j=0 ; j<m ; j++ ){
if( isReserved[i][j] ) {
isPrevReserved = true;
nFree = 0;
}else{
isPrevReserved = false;
nFree++;
}
if( nFree >= 2 ) nSeat++;
}
}
return nSeat;
}
}
得点は220.85/250、1回のsubmitでシステムテストクリア。「並び」、「行」と訳したのですが、まとめた方がよかったですかねぇ。
2013年7月4日木曜日
TopCoder SRM468 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
王は長いこと外におり、妃の元へできるだけ早く戻りたいと思っている。王は街0におり、妃は街Nにいる。0からN-1の間の値をとる各iにおいて、街iと街i+1を結ぶ道と空路が存在する。i番目の要素がiからi+1へ向かうのに陸路でかかる時間を表すroadTime[]と、空路でかかる時間flightTime[]が与えられる。しかし、空路を選ぶことは王国における技術的な制限により王の命に危険がある。したがって、妃は王に最大でK回のフライトにするように頼んでいる。王が妃のもとにたどり着くまでにかかる最小の時刻を計算して返せ。
私の解答はこちら。
import java.util.Arrays;
public class RoadOrFlightEasy {
public int minTime(int N, int[] roadTime, int[] flightTime, int K) {
int[] diff = new int[N];
int time = 0;
for( int i=0 ; i<N ; i++ ){
diff[i] = roadTime[i] - flightTime[i];
}
for( int i=0 ; i<N ; i++ ){
time += roadTime[i];
}
Arrays.sort(diff);
if( diff[N-1] <= 0 ) return time;
int k = 0;
for( int i=N-1 ; i>=0 ; i-- ){
if( k >= K || diff[i] <= 0 ) break;
time -= diff[i];
k++;
}
return time;
}
}
得点は201.00/250、2回目のsubmitでシステムテストクリア。最後に「|| diff[i] <= 0」を付け忘れての失敗。方針としては、iからi+1へ陸路と空路で向かった時にかかる時間の差をとり、空路の方が速いものから、最大K個とるというものである(実際の計算では陸路で全部向かったと仮定して、差分だけ引き算するようにしている)。ただし、速い方からK個とるうちに、陸路の方が速く到着するようであれば、それ以上は空路を選択せずに終了とする。
2013年7月2日火曜日
TopCoder SRM467 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
SuperSumは次のように定義される関数である:
- すべての正数nに対して、SuperSum(0, n) = n
- 任意の正数n, kに対しSuperSum(k, n) = SuperSum(k-1, 1) + SuperSum(k-1, 2) + ... + SuperSum(k-1, n)
さて、kとnが与えられたとき、SuperSum(k , n)の値を求めよ。
私の解答はこちら。
public class ShorterSuperSum {
public int calculate(int k, int n) {
return SuperSum(k, n);
}
private int SuperSum(int k, int n){
int num = 0;
if( k <= 0 ) return n;
for( int i=1 ; i<=n ; i++ ){
num += SuperSum(k-1, i);
}
return num;
}
}
得点は248.15/250、1回のsubmitでシステムテストクリア。
2013年7月1日月曜日
2013年6月の学習記録
ようやくWindows機を購入。これでやる気が回復するか!?そして積読候補をまた増やしてしまいました。実務に関連しそうなので、ついでにやってしまおうと思っているのですが、どこまでできることやら。
- CentOS 6で作るネットワークサーバ構築ガイド
- メールサーバ、メーリングリストサーバの調査で50ページほど読みました。
- ノンパラメトリック統計入門(pp.137〜210)
- 適合度検定について。Rで使えば一発で結論は出るが、その裏のアイディアを知ることができます。適合度検定は定番の分析手法で基本的なテキストなら大概出てくるのですが、どの本にも自由度の説明がないんですよね。具体的にはカテゴリ数がrとcだけある場合に、適合度検定を行うと自由度が(r-1)*(c-1)のカイ二乗分布に従うということなのですが、この証明があるテキストは何処?
その他、「統計学が最強の学問である」を半分ほど。適用範囲の広さだけなら最強かも。
2013年6月17日月曜日
2013年5月の学習記録
やっぱりWindowsマシン買わないと駄目ですね。TopCoderを解こうという気持ちに持って行けないです。
- CentOS 6で作るネットワークサーバ構築ガイド
- DNSサーバ、メールサーバの調査で120ページほど読みました。
- ノンパラメトリック統計入門(pp.1〜136)
- 符号検定やウィルコクソンの順位和検定など、アイディアとしては単純なのでここまでは納得しやすい感があります。
2013年5月30日木曜日
2013年4月の学習記録
自宅で作業するのに使っていたWindowsマシンが不調でブログを書く意欲を失っていたのですが、何も書かない月があるのもいかがかと思うので記録しておきます。
- CentOS 6で作るネットワークサーバ構築ガイド
- SSHやWebサーバのセキュリティ関係の調査で150ページほど読みました。
その他、統計関連の試験勉強を少々。今月から忙しさがグッと変わって、読書量が減ってしまいました。学習するためのリズムを作る必要がありますね。今年度はインフラ、Webプログラミングと統計学の学習をしていきたいと思います。サーバを知らないとセキュリティ対策などでWebシステムを上手く組めないので、まずはサーバから始めています。半年ぐらいでLPIC level 1が合格できる程度になりたいです。
2013年4月17日水曜日
統計検定1級合格体験記
2012年に実施された統計検定1級(と2級)に合格していました。自信を持って完答できたのは解答した6問のうち1問のみ(残りは半答程度)なので、ギリギリの合格とは思いますが、今後学習する人の参考になればということで参考書や感想などを挙げておきます。
- 学習時間
- 選択分野
- 統計数理参考書
- 統計応用参考書
- 攻略法
本格的に勉強をする前は2級が受かるかなという程度でした。試験対策では400時間程度学習しました。今思うと学習前は大変無知な状態だったと思います。
理工学を選択しました。ここはかなり人によって選択が変わってくると思います。統計なんて一括りにしてはいけません。統計の研究室に所属してますと言っても、(経済と生物のように)専門分野が違うと話が通じることはほぼ期待できません。過去問も出てきたので、向き不向きを見極めて慎重に選択してください。
統計検定1級の対策テキストは最近出たようです。統計数理分野のみならテキストを作れると思いますが、統計応用は広すぎてキーワード中心になってしまっているようです(完全網羅するテキストを作ったら1000ページぐらいになってもおかしくない)。受験当時は対策本が存在していなかったので、統計解析入門(赤平)、入門・演習 数理統計(野田・宮岡)を読んでいました。変数変換や順序統計量、フィッシャー情報量などが網羅されているレベルの本(学部3~4年程度)を読破すると、必答問題に対応できると思います。推定・検定で終わるような学部教養レベルの本は2級程度の対応止まりなので、副読本選びには要注意。
理工学の問題では欠測データと実験計画法の問題が出ました。不完全データの統計解析(岩崎)、よくわかる実験計画法(中村)を読んでいたことが試験に生きたかなと思います。統計応用の問題は曲者で、当日選択できません。当たり所が悪いとまったく手が出せない恐れがあります。全く知らない分野ではなかったので助かりました。
出題者の癖を知るということで、問題製作者の本を読んでみるのがよいかもしれません。
まだ初回なので、今後試験形式が変わることもあるかもしれません。大きすぎる言い回しかもしれませんが、今後、統計検定などを通じて"正しい"データ解析の文化がさらに普及することを期待しています。
2013年4月14日日曜日
TopCoder SRM466 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ニックは宝くじを買うのが好きである。くじを1つ買う費用はpriceである。ニックはb1~b4までの紙幣を持っている(一緒の値になることもある)。ニックはおつりなしでくじを買えるかどうかを知りたがっている。言い換えれば、持っている紙幣の一部だけを使ってきっちりpriceを支払いたいということである。もし可能であれば"POSSIBLE"を、そうでなければ"IMPOSSIBLE"を返せ。
私の解答はこちら。
public class LotteryTicket {
public String buy(int price, int b1, int b2, int b3, int b4) {
int total = 0;
for( int i=0 ; i<2 ; i++ ){
for( int j=0 ; j<2 ; j++ ){
for( int k=0 ; k<2 ; k++ ){
for( int l=0 ; l<2 ; l++ ){
total = 0;
if( i == 1 ) total += b1;
if( j == 1 ) total += b2;
if( k == 1 ) total += b3;
if( l == 1 ) total += b4;
if( total == price ) return "POSSIBLE";
}
}
}
}
return "IMPOSSIBLE";
}
}
得点は244.99/250、1回のsubmitでシステムテストクリア。単純に全部のパターンを試すだけです。すべてのパターンを生成する方法は、本問のように4重ループ程度なら良いですが、100重ループとかになったら考えものでしょうね。
2013年4月13日土曜日
TopCoder SRM465 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
numbers[]という整数型配列が与えられたときに、隣り合う数字のペアの数を返せ。隣り合う数字のペアというのは、数字を並び替えて作ることができる数字で先頭の0を除去したときに一致するものがあることをいう。例えば40020と204は00024と024と並び替えて先頭の0を除くと一致するので隣り合う数字のペアである。
私の解答はこちら。
import java.util.ArrayList;
import java.util.Arrays;
public class NumberNeighbours {
public int numPairs(int[] numbers) {
int nPair = 0;
for( int i=0 ; i<numbers.length ; i++ ){
for( int j=i+1 ; j<numbers.length ; j++ ){ // 探索範囲のインデックスに注意
char[] s1 = ("" + numbers[i]).toCharArray(); // 各ペアを文字列に変換して
char[] s2 = ("" + numbers[j]).toCharArray();
s1 = removeZeros(s1); // 0を文字列から取り除いて
s2 = removeZeros(s2);
Arrays.sort(s1); // 文字コードでソートして
Arrays.sort(s2);
if( Arrays.equals(s1, s2)) nPair++; // 一致していれば隣り合う数字のペアとなる
}
}
return nPair;
}
private char[] removeZeros(char[] cs){
ArrayList<Character> ret = new ArrayList();
for( int i=0 ; i<cs.length ; i++ ){
if( cs[i] != '0' ) ret.add(cs[i]);
}
return ret.toString().toCharArray();
}
}
得点は194.99/250、1回のsubmitでシステムテストクリア。この問題は軍隊がどうのこうのという設定があるのですが、本質的に関係ないので特に訳してません。
2013年4月7日日曜日
2013年3月の学習記録
2013年3月に学習した主な本一覧。月末に引越が絡んで何もできないような感じになってしまいました。
- Rによる統計解析ハンドブック(pp.185~200)
- 演習問題が難しく、1つの章の問題をすべてを回答するのは難しい感じがありますね。
- はじめての集合と位相(pp.61~83)
- 演習問題の解答が欲しい...
- 人文・社会科学の統計学(pp.59~78)
- うーん、経済データの解析や時系列という感じではないんですよね。多変量解析や生物統計の方が性に合っているのかもと思いました。
英文ドキュメント翻訳の作業はWriting R Extensionsでした。次のバージョン(2.15.3)が出た直後でのリリースとなってしまいましたが、間瀬先生が翻訳をされて10年以上が経過して、随分と内容が変わってしまっていたので作成した次第です。TopCoderの演習は4問。
2013年3月20日水曜日
Writing R Extensions (version 2.15.2) 日本語訳を公開しました!
R 2.15.2 用に書かれたWriting R Extensionsを日本語に翻訳したドキュメント「Rの拡張を書く」を公開しました。slideshareからダウンロードできます。
Rを含め、統計学の更なる普及を期待して作成いたしました。是非ご活用ください。
2013年3月11日月曜日
C言語の関数中における文字列の交換
文字列を関数の仮引数として渡して、その交換を行う際には多少注意が要る。以下の例では、char *型の変数にポインタを通じてアクセスするので、呼び出す関数ではchar **型にする必要がある。関数に渡すものはアドレスなので、実引数はchar *型変数のアドレスとする必要がある(つまり&をつける)。比較のため、整数型変数を交換する場合と共にそのコードを示す。
#include <stdio.h>
void swap_int(int *a, int *b){
int tmp = *a;
*a = *b;
*b = tmp;
}
/* 仮引数は*aaではなく**aaになることに注意 */
void swap_str(char **aa, char **bb){
char *tmp = *aa;
*aa = *bb;
*bb = tmp;
}
int main(void){
int x = 10;
int y = 20;
char *a = "hello";
char *b = "world";
printf("x = %d, y = %d\n", x, y); /* x = 10, y = 20 */
swap_int(&x, &y);
printf("x = %d, y = %d\n", x, y); /* x = 20, y = 10 */
printf("a = %s, b = %s\n", a, b); /* a = hello, b = world */
swap_str(&a, &b);
printf("a = %s, b = %s\n", a, b); /* a = world, b = hello */
return 0;
}
2013年3月4日月曜日
2013年2月の学習記録
2013年2月に学習した主な本一覧。
- Rによる統計解析ハンドブック(pp.100~184)
- 演習問題がちょっと難しくなってきましたね...
- はじめての集合と位相(pp.13~61)
- 実数やグラフなど、高校生の頃には疑問に思わなかったことを説明しているので、目から鱗です。
- HTML/XHTML&スタイルシートデザインブック(pp.1~314 読了)
- マウスが重なった時に画像を切り替える方法はJavaScriptしかないと思っていた。しかし、上に通常の状態の画像、下にマウスのアイコンが重なった時の画像を並べた画像を用意しておいて、マウスが重なった時に画像を表示する基準位置をCSSを使って切り替えるという方法でhtml+CSSのみでできるという手法が紹介されていたことが衝撃的でした。
- 詳解C言語 ポインタ完全攻略(pp.261~326 読了)
- 人文・社会科学の統計学(pp.1~58)
英文ドキュメント翻訳の作業は約92%まで到達。リリースまであと10日ぐらいかと予想してます。
2013年2月27日水曜日
TopCoder SRM464 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
numRedの赤い箱、numBlueの青い箱、numRedの赤い球、numBlueの青い球を使うゲームをしている。各ボールを箱に入れる。各箱は以下のようにして点数がつけられる。
- 箱が赤で赤い球を含んでいればonlyRed点得る。
- 箱が青で青い球を含んでいればonlyBlue点得る。
- それ以外はbothColors点得る。
合計点はすべての箱の点数の合計である。可能性がある得られる点数の最大値を返せ。
私の解答はこちら。
public class ColorfulBoxesAndBalls {
public int getMaximum(int numRed, int numBlue, int onlyRed, int onlyBlue, int bothColors) {
int same = numRed * onlyRed + numBlue * onlyBlue;
int diff;
if( numRed < numBlue ){
diff = bothColors * numRed + bothColors * numRed + onlyBlue * (numBlue - numRed);
}else{
diff = bothColors * numBlue + bothColors * numBlue + onlyRed * (numRed - numBlue);
}
return Math.max(same, diff);
}
}
得点は232.88/250、1回のsubmitでシステムテストクリア。可能性があるのは箱と球の色がすべての箱で完全一致した場合と、できるだけ箱と球の色が一致しないようにした場合の2種類のみなので、それらについてのみ点数を検討すればOK。
2013年2月26日火曜日
TopCoder SRM463 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
タロウとハナコはバニーパズルで遊んでいる。1列にウサギが何匹か並んでいて、各ウサギの位置はbunnies[](昇順にソート済)という整数型配列で与えられている。ウサギは次のように1度だけ振る舞う:aとbの位置にいるウサギAとBを選ぶ。AはBを飛び越え2*b-aの位置に飛ぶ。もしその位置にウサギが既にいれば飛ぶことはできない。複数匹のウサギを飛び越えることもできない。以上の条件が成り立つとき、AとBの選び方の総数を返せ。なおAがBを飛び越えるのと、BがAを飛び越えるのは異なるものとする。
私の解答はこちら。
public class BunnyPuzzle {
public int theCount(int[] bunnies) {
int n = 0;
// 左のウサギがその右の位置にいるウサギを飛び越える
for( int i=0 ; i<bunnies.length ; i++ ){
if( i == bunnies.length-2 ){ // 一番右の2匹の組は成立するペア
n++;
break;
}
int cur = bunnies[i];
int tar = bunnies[i+1];
int jumpto = bunnies[i] + 2 * (tar - cur);
if( jumpto < bunnies[i+2] ) n++;
}
// 右のウサギがその左の位置にいるウサギを飛び越える
for( int i=bunnies.length-1 ; i>=1 ; i-- ){
if( i==1 ){ // 一番左の2匹の組は成立するペア
n++;
break;
}
int cur = bunnies[i];
int tar = bunnies[i-1];
int jumpto = bunnies[i] + 2 * (tar - cur);
if( jumpto > bunnies[i-2] ) n++;
}
return n;
}
}
得点は166.60/250、1回のsubmitでシステムテストクリア。全部の組を探索する必要はなく、隣り合う2匹に着目するのが簡単と気付くまでちょっと時間がかかりました。
2013年2月23日土曜日
TopCoder SRM462 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
アーチェリーでは、矢を標的に放ち標的の当たった位置によって得点を得る。この問題では、標的はN個の輪と中央の円からなるものとする。輪の幅と中央の円の半径は等しいとする。各目標の位置に割り当てられた得点は整数型の配列ringPoints[]で与えられる。得点は内側から外側へ順に与えられており、添字0は中央の円、添字Nは一番外側の輪の得点である。あなたはアーチェリーを始める。矢を放つたびに標的のランダムな場所に当たり、どの位置にあたる確率も等しいものとする。矢を放ったときの得点の期待値を返せ。
私の解答はこちら。
public class Archery {
public double expectedPoints(int N, int[] ringPoints) {
int total = 0;
for( int i=0 ; i<ringPoints.length ; i++ ){
// 各位置に当たる割合は内側から順に1, 3, 5, ..., 2N+1となる
total += ringPoints[i]*(2*i+1);
}
return total*1.0/((N+1)*(N+1)); // 1+3+...+(2N+1)=(N+1)^2で割って正規化
}
}
得点は225.79/250、1回のsubmitでシステムテストクリア。
2013年2月19日火曜日
Rによる統計解析ハンドブック 第8章演習問題解答
This post is solutions of the chapter 8 of `A Handbook of Statistical Analyses Using R, Second Edition'. Chapter 6 and 7 will be posted later.
このポストはRによる統計解析ハンドブック(第2版)の第8章の解答になります。第6, 7章については後日掲載する予定です。
1
Although it is difficult to discern from the histogram, result of which kernel band is 3000 indicates that there are 6 peaks in density function. As kernel band gets lerger, we can't discern all of 6 peaks because they are mixed.
ヒストグラムからは判別しにくいが、カーネル幅が3000のときの結果から、密度関数からは峰が6つあることが示唆される。カーネル幅が大きいと峰が混ざるため、すべて判別できなくなる。
data("galaxies", package="MASS")
oldpar <- par(mfrow=c(2, 2))
do <- function(dat, ker, wid){
h.info <- hist(dat, plot=FALSE)
d.info <- density(dat, kernel=ker, width=wid)
yr <- range(c(0, h.info$density, d.info$y))
tit <- paste(ker, "kernal width = ", wid, collapse=" ")
hist(dat, probability=TRUE, ylim=yr, main=tit)
lines(d.info, lwd=2)
}
do(galaxies, "gaussian", 3000)
do(galaxies, "gaussian", 5000)
do(galaxies, "triangular", 3000)
do(galaxies, "triangular", 5000)
par(oldpar)
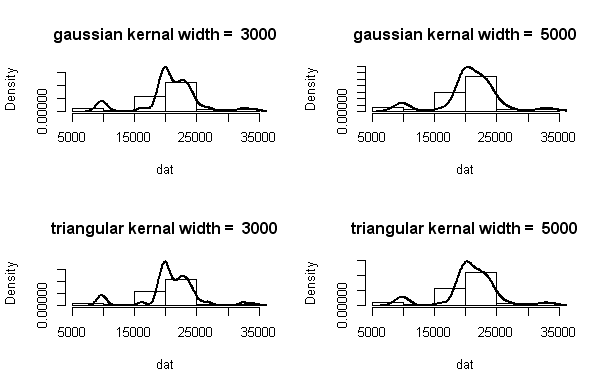
2
Data can be seen around (20, 10), and we can see that death rate is constant with birth one.
データは(20, 10)近辺に多く見られ、0.001の等高線からは出生率に関係なく死亡率は一定に近い傾向があることが見て取れる。
library(KernSmooth)
data("birthdeathrates", package="HSAUR2")
bdr.d <- bkde2D(birthdeathrates, bandwidth=sapply(birthdeathrates, dpik))
contour(bdr.d$x1, bdr.d$x2, bdr.d$fhat,
xlab=names(birthdeathrates)[1], ylab=names(birthdeathrates)[2],
main="estimated density of birthdeathrates")

3
Note that plot.Mclust doesn't reflect option such as col and ylim. Graphs show that there is modality for female, and tendency that male develops schizophrenia earlier than female (Note that vertical axis is different between two graphs).
plot.Mclustはcol、ylimなどのオプションを指定しても反映されないことに注意。グラフを見ると、女性は二峰性があり、男性は女性よりも若いころに発症する傾向がある(縦軸の値が異なることに注意)。
library(mclust)
data("schizophrenia", package="HSAUR2")
# previous consideration (事前の考察)
boxplot(age~gender, data=schizophrenia, main="age distribution")
# split data(データの分割)
female <- subset(schizophrenia, gender=="female", select=age)
male <- subset(schizophrenia, gender=="male", select=age)
mc.fem <- Mclust(female)
mc.mal <- Mclust(male)
oldpar <- par(mfrow=c(1, 2))
plot(mc.fem, what="density", xlim=c(0, 70), ylim=c(0, 0.06))
plot(mc.mal, what="density", xlim=c(0, 70), ylim=c(0, 0.06))
par(oldpar)

2013年2月17日日曜日
TopCoder SRM461 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
1000*1000の格子で表された草原がある。最初にウサギは(1, 1)の座標にいる(添字は1から始まる)。ウサギは水平方向と垂直方向の隣り合う地域へ1秒で移動することができ、その方法でのみ動くことができる。さて、あなたはウサギを罠にかけようとしている。そのために、いくつかの罠をしかけた。i番目の罠はtrapX[i]、trapY[i]で与えられ、それぞれ罠のX、Y座標を表している。ウサギが罠にはまる可能性が0とならない経過時間の最小値を返せ(罠にはまるというのは、罠のある位置にウサギが移動することをいう)。
私の解答はこちら。
public class TrappingRabbit {
public int findMinimumTime(int[] trapX, int[] trapY) {
int minSum = 2000;
for( int i=0 ; i<trapX.length ; i++ ){
minSum = Math.min(minSum, trapX[i]+trapY[i]);
}
return minSum-2;
}
}
得点は246.48/250。1回のsubmitでシステムテストクリア。単純に一番マンハッタン距離の近い罠の座標から2を引くだけです。
2013年2月13日水曜日
TopCoder SRM460 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
あるボリビア人がquestions[]という文字列の内容のインタビューをボリビアで有名なジョンにしたが、インタビューの回答を紛失してしまった。なお、質問の内容はすべてYesまたはNoで答えられるものである。同じ質問をしていることがあるが、ジョンはすべて常に同じ回答をしている。さて、そのボリビア人は質問の内容から回答のパターンをすべて書き出そうとしているのだが、それは全部で何通りになるか計算して返せ。
私の解答はこちら。
import java.util.ArrayList;
public class TheQuestionsAndAnswersDivTwo {
public int find(String[] questions) {
ArrayList<String>al = new ArrayList<String>(); // ユニークな質問の文字列をすべて記録
for( int i=0 ; i<questions.length ; i++ ){
if( al.contains(questions[i]) == false ) al.add(questions[i]);
}
return (int)Math.pow(2, al.size());
}
}
得点は243.23/250、1回のsubmitでシステムテストクリア。質問の種類数をカウントすればあとは簡単。
2013年2月11日月曜日
TopCoder SRM459 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
平面にsideLengthの長さを持つ正方形を描く、次に円を内接するように描く。その縁の中に内接するように正方形を描く。これを平面にK個の円が現れるまで手続きを繰り返す。各円について他の図に重ならない面積を求め、その面積の合計を返せ。
私の解答はこちら。
public class RecursiveFigures {
public double getArea(int sideLength, int K) {
double area = sideLength * sideLength; // 全体の面積
double currentSideLen = sideLength; // 注目する正方形の辺の長さ
for( int i=0 ; i<K ; i++ ){
area -= currentSideLen * currentSideLen; // 正方形の面積を引き
area += (currentSideLen/2)*(currentSideLen/2) * Math.PI; // 次の円の面積を足す
currentSideLen = currentSideLen/Math.sqrt(2); // 次の正方形の辺は現時点から1/sqrt(2)倍
}
return area;
}
}
得点は236.29/250、1回のsubmitでシステムテストクリア。ちょっと手順の構成につまりました。もっと単純にできるかもしれないですね。
2013年2月7日木曜日
Rによる統計解析ハンドブック 第5章演習問題解答
This post is solutions of the chapter 5 of `A Handbook of Statistical Analyses Using R, Second Edition'.
このポストはRによる統計解析ハンドブック(第2版)の第5章の解答になります。
1
Estimated values are larger than actual ones for pair of beef and low or that of cereal and high. Otherwise these are lower than that. B, C, L, H in the below graph stand for Beef, Cereal, Low and High.
牛肉で低たんぱく質、穀物で高たんぱく質は推定値が大きめになり、それ以外は推定値が低めに出ている。グラフ中のB、C、LとHはそれぞれBeef、Cereal、LowとHighの頭文字をとったものであることに注意。
data("weightgain", package="HSAUR2")
resid <- weightgain$weightgain - aov(weightgain ~ source + type, data=weightgain)$fitted.values
plot(resid, type="n", main="residuals")
lab <- paste(abbreviate(weightgain[,1],minlength=1),
abbreviate(weightgain[,2],minlength=1), sep="")
text(resid, label=lab)

2
The result of plot.design shows no effect on gender and learner. So I conducted anova only with race and school. Race is only affects absent days in conclusion. Note that if anova is conducted with all vatiable, f-value of learner is smaller than 1 and it should be pooled.
plot.designからgender、learnerは関係なさそうとなる。そこで、人種、学年のみを使って分散分析を行った。結論としては欠席日数に効いているのは人種であると言える。なお、全変数で分散分析をかけると、learnerのF値が1より小さくプーリングすべきと考えられる。
data("schooldays", package="HSAUR2")
plot.design(schooldays)
aov.res <- aov(absent ~ race * school, data=schooldays)
anova(aov.res)
interaction.plot(schooldays$race, schooldays$school, schooldays$absent)
> anova(aov.res)
Analysis of Variance Table
Response: absent
Df Sum Sq Mean Sq F value Pr(>F)
race 1 2645.7 2645.65 12.4615 0.0005561 ***
school 3 1325.5 441.85 2.0812 0.1052455
race:school 3 3738.2 1246.08 5.8693 0.0008221 ***
Residuals 146 30996.7 212.31
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
3
By executing below code, we find that the hypothesis of the uniformity of mean values are rejected between any two groups.
以下のコードを実行すると、任意の2グループ間で、平均値の同等性の仮定は棄却されることが分かる。
data("students", package="HSAUR2")
students.manova <- manova(cbind(low, high) ~ treatment, data=students)
summary(students.manova, test="Hotelling-Lawley") # p-value is very small!
summary.aov(students.manova)
summary(manova(cbind(low, high) ~ treatment, data=students,
subset = treatment %in% c("AA", "C")))
summary(manova(cbind(low, high) ~ treatment, data=students,
subset = treatment %in% c("C", "NC")))
summary(manova(cbind(low, high) ~ treatment, data=students,
subset = treatment %in% c("NC", "AA")))
2013年2月3日日曜日
TopCoder SRM458 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
砂漠化がボブの島では深刻な問題である。ボブの島はセルの格子が長方形になっている。island[]というボブの島の状態が与えられる。i番目の要素のj番目の文字が島のi行j列の土地の状態を表し、Dが砂漠、Fが森を表す。砂漠の広がり方は1年後に砂漠が上下左右のセルに広がるというものである。砂漠はつねに砂漠でありつづける。T年後の砂漠のセル数を返すメソッドを作成せよ。
私の解答はこちら。
public class Desertification {
public int desertArea(String[] island, int T) {
int nRow = island.length;
int nCol = island[0].length();
int S = nRow * nCol; // セルの総数
boolean[][] isDesert = new boolean[nRow][nCol]; // 今年砂漠かを記録
boolean[][] nextDesert = new boolean[nRow][nCol]; // 翌年砂漠かを記録
for( int i=0 ; i<nRow ; i++ ){ // 砂漠の位置を記録
for( int j=0 ; j<nCol ; j++ ){
if( island[i].charAt(j) == 'D' ) isDesert[i][j] = true;
}
}
if( countTrueGrid(isDesert) == 0 ) return 0; // 砂漠がなければ砂漠はできないので0で終了
for( int t=0 ; t<T ; t++ ){ // 砂漠の位置を拡散する
for( int i=0 ; i<nRow ; i++ ){
for( int j=0 ; j<nCol ; j++ ){
if( isDesert[i][j] == true ){
nextDesert[i][j] = true;
if( i-1 >= 0 ) nextDesert[i-1][j] = true;
if( j-1 >= 0 ) nextDesert[i][j-1] = true;
if( j+1 < nCol ) nextDesert[i][j+1] = true;
if( i+1 < nRow ) nextDesert[i+1][j] = true;
}
}
}
for( int i=0 ; i<nRow ; i++ ){
for( int j=0 ; j<nCol ; j++ ){
isDesert[i][j] = nextDesert[i][j];
}
}
if( countTrueGrid(isDesert) == S ) return S; // 全部砂漠になったら終了
}
int nTrue = 0;
for( int i=0 ; i<nRow ; i++ ){ // 最後の砂漠のセル数を数える
for( int j=0 ; j<nCol ; j++ ){
if( isDesert[i][j] ) nTrue++;
}
}
return nTrue;
}
private int countTrueGrid(boolean[][] bl){ // 現在の砂漠のセル数をカウントする関数
int n = 0;
for( int i=0 ; i<bl.length; i++ ){
for( int j=0 ; j<bl[i].length ; j++ ){
if( bl[i][j] ) n++;
}
}
return n;
}
}
得点は203.52、1回のsubmitでシステムテストクリア。Tが10億まで取れるので、Tが大きい値になったときの対処が必要です。
2013年2月2日土曜日
TopCoder SRM457 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ジョンとブラスはパズルが好きである。彼らは正方形の盤面にチェッカーを置く新しいゲームをしている。盤面は格子状で同じ数の行と列を持つ。ゲームはジョンがチェッカーを盤面のセルに置くことから始まる。つぎにR[i]が各行iに対して計算される。R[i]はi番目の行にあるチェッカーの数である。盤面のi列目のチェッカーの数がR[i]になるようにブラスはチェッカーを動かさなければならない。R[i]はチェッカーの初期配置から計算され、途中で修正されないことに注意。1回のターンでブラスはチェッカーを上下左右の空いているセルに動かすことができる。目標に届くまで必要なターンを使うであろう。board[]という文字列型配列が与えられる。i番目の要素のj番目が'C'であれば盤面のi行j列のセルにチェッカーがあり、そうでなければ'.'となっている。最後の配置の状態を入力と同じ形式を使って返せ。配収的な配置は多い可能性があるので、辞書順で最も早くなるものを返せ。
私の解答はこちら。
public class TheSquareDivTwo {
public String[] solve(String[] board) {
int size = board.length; // 行、列のサイズ
char[][] cells = new char[size][size]; // i行j列のセルに入る値を記録
int[] nC = new int[size]; // 各列方向にいくつ置くかを記録する
for( int i=0 ; i<board.length ; i++ ){
for( int j=0 ; j<size ; j++ ){
if( board[i].charAt(j) == 'C' ) nC[i]++;
}
}
// 列ごとに配置。辞書順で最初に来る物ということなので、上に'.'、下に'C'が
// 来るようにする必要がある。'C'の数はnC[i]を参照すればよい。
for( int j=0 ; j<size ; j++ ){
for( int i=0 ; i<size ; i++ ){
if( size - nC[j] - i > 0 ){
cells[i][j] = '.';
}else{
cells[i][j] = 'C';
}
}
}
for( int i=0 ; i<size ; i++ ){ // 文字型配列を文字列に変換
board[i] = String.valueOf(cells[i]);
}
return board;
}
}
得点は169.41、1回のsubmitでシステムテストクリア。本文は分かりにくかったのですが、出力例を見てアルゴリズムをようやく理解。
2013年2月1日金曜日
2013年1月の学習記録
2013年1月に学習した主な本一覧。今年度も終盤に差し掛かってきました。
- 入門・演習 数理統計(演習15問)
- とりあえずdone。次はHoggの本でも読もうかな?
- カウントデータの統計解析(pp.153~189読了)
- 統計検定1級と同じデータが出てきてて、著者が出題者でもあったので、あーなどと思いながら最後まで読みました。
- Beautiful Visualization(pp.26~読了)
- データ可視化のためのTips集。まだこの分野は未開な感じがしました。芸術の側面もあるので、これ!と言い切れる手法が確立されて無いのかなと思います。
- Rによる統計解析ハンドブック(pp.1~100)
- 少しでも統計の本を読み終えてから読みましょう。解答がないので、自作中。
- 詳解C言語 ポインタ完全攻略(pp.1~260)
- 思い出すために読書中。相変わらずポインタは紛らわしいですね。
- はじめての集合と位相(pp.1~12)
- とりあえず1章だけ。章末の問題に解答があると親切なのですがね...
その他、TopCoderの過去問を6問解く。線形空間の本を読もうかとも思ったが、まだ知らない位相を学ぶ本を読む方針に変更した。英文ドキュメント翻訳の作業は約65%まで到達。Ruby on Railsを触ってみたいと思うのですが、近いうちに次のバージョンが出るので、そのときに出版された書籍を買って読みたいかなと思います。
2013年1月30日水曜日
Rによる統計解析ハンドブック 第4章演習問題解答
This post is solutions of chapter 4 of `A Handbook of Statistical Analyses Using R, Second Edition'.
このポストはRによる統計解析ハンドブック(第2版)の第4章の解答になります。
1
Test based on chi-square can't reject independency of region and site of lesion, but Fisher's exact test rejects that.
カイ2乗値に基づく検定では地域と病変部位は独立でないと言えないが、Fisherの正確検定では棄却される。
data("orallesions", package="HSAUR2")
chisq.test(orallesions) # p-value = 0.1096, accept
fisher.test(orallesions) # p-value = 0.01904, reject
2
labels in graph warp each other, so should I change row names of the dataframe to avoid wapping in advance?
グラフのラベルが重なるのですが、予めrownames関数でデータフレームの行名を変えなければならないのでしょうか。
library("vcd")
data("orallesions", package="HSAUR2")
assoc(orallesions)
mosaic(orallesions)
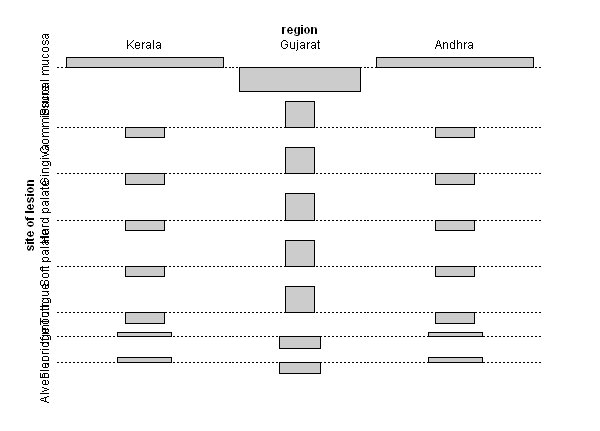
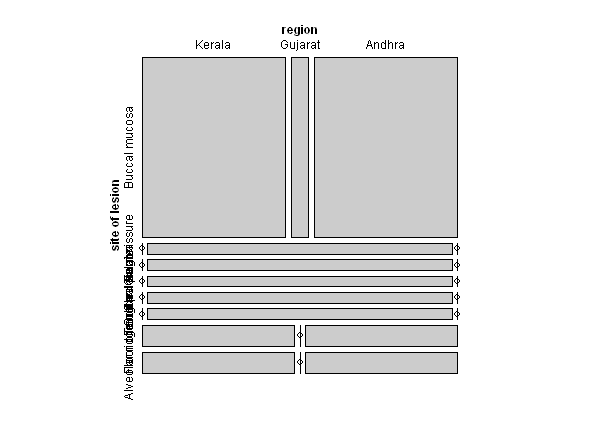
3
Difference of p-value is derived from the that of mean. To check this, boxplot is helpful. By executing sum(p.diff>0) in R, it turns out that elements of p.diff is always larger than 0.
違いは平均値の差の大きさに由来する。これを確認するためには箱ひげ図が便利である。Rでsum(p.diff>0)とすることで、すべて0より大きな値をとっていることが分かる。
library("coin")
n.test <- 100 # number of test
p.diff <- matrix(nrow=n.test, ncol=4) # matrix to store the difference of p-value
colnames(p.diff) <- c("diff=0.5", "diff=1", "diff=1.5", "diff=2")
sz <- 12 # 15 is upper limit on my computer. Be sure to make sz less than 15!
for( i in 1:n.test ){
for( j in 1:4 ){
g1 <- rnorm(sz, mean=0, sd=1)
g2 <- rnorm(sz, mean=j/2, sd=1)
lev <- c(rep(1, sz), rep(2, sz))
ddd <- c(g1, g2)
gs <- as.data.frame(cbind(ddd, lev))
colnames(gs) <c("value", "gr")
gs$gr <- factor(gs$gr)
p.diff[i, j] <pvalue(wilcox_test(value ~ gr, data=gs, distribution=exact()))
- pvalue(independence_test(value ~ gr, data=gs, distribution=exact()))
}
}
boxplot(p.diff)

2013年1月27日日曜日
Rのpairs関数の出力をカスタマイズする
pairs関数(対散布図とも言う)はデフォルトの設定では黒い点でプロットするだけなので、グラフにより情報を持たせるため、グラフをカスタマイズする。対散布図は行方向、列方向に同じ数の図が描かれるが、i行j列の位置にある図とj行i列の位置にあるグラフは実質同じなので、工夫したグラフを試してみようということである。
ここではおなじみのirisデータを基に、右上のグラフには相関係数の絶対値、左下のグラフにはデータを色で分けたグラフと、直線性が強い組についてのみ回帰直線を描いてみることにする。
右上、左下のグラフを制御するのはpairs関数の引数のうち、panel、upper.panel、lower.panelである。デフォルトではpanelは散布図を描くようになっており、upper/lower.panelはそれを使うようになっているので、点による散布図が書かれることになる。upper/lower.panelの引数に与える関数を書き換えることで、グラフに手を加えることができる。
upper <- function(x, y, ...){ # 右上の散布図を設定
oldpar <- par(usr = c(0, 1, 0, 1)) # 3行下でテキストの位置を(0.5, 0.5)にするための調整
v <- abs(cor(x, y))
sz <- 1 + v * 2 # テキストのサイズを直線性の強さで調整
text(0.5, 0.5, sprintf("%.3f", v), cex = sz)
par(oldpar)
}
lower <- function(x, y, ...){ # 左下の散布図を設定
points(x, y, pch = 21, bg = c("red", "green3", "blue")[unclass(iris$Species)])
if( abs(cor(x, y)) > 0.8 ){ # 直線性の強いデータの組だけ回帰式を作成
lmobj <- lm(y~x)
abline(lmobj)
}
}
pairs(iris[,1:4], upper.panel=upper, lower.panel=lower)
気をつける必要があるのは、lower関数の1行目で、ここでplotを用いて書こうとするとエラーになる点である。低水準作図関数を使うようにすること。また、lower関数内で用いたpoints関数のbgパラメータのように、データをそのまますべて渡せば、すべての散布図で自動的にうまく描いてくれる。1つ1つの散布図を気にしてパラメータを変更する必要はない。
上のコードを実行すると、次のような画像が得られる。
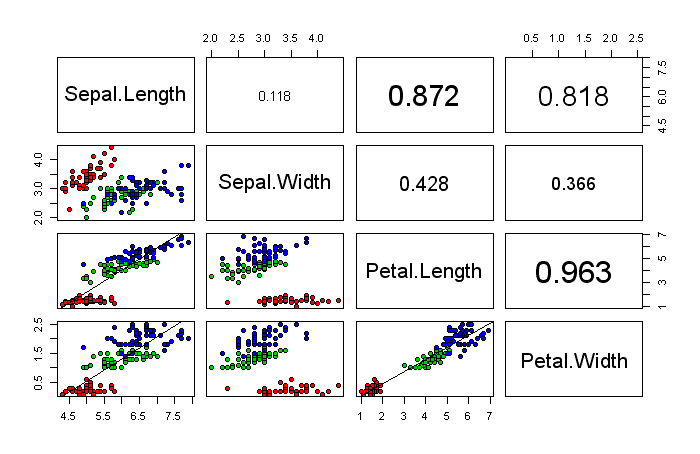
2013年1月25日金曜日
TopCoder SRM455 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ペーチャは蜘蛛が好きである。彼は蜘蛛を長方形の格子の各セルに1匹づつ置いた。ペーチャは何年も蜘蛛について研究してきたので、すべての蜘蛛の動きを予想した。各秒の初めにすべての蜘蛛がセルから隣り合うセルのどれか1つに移動する(あるいは格子から離れる)。各セルにペーチャは蜘蛛の動きの方向を書いており、それはA[]という文字列型配列で与えられる。i番目の要素のj番目の文字はNSEWのいずれかであり、それぞれ北、南、東、西方向への移動を表している。もし格子の外側に移動したら、床に落ちる。1秒後に空いているセルの数を返せ。
私の解答はこちら。
public class SpidersOnTheGrid {
public int find(String[] A) {
int nRow = A.length;
int nCol = A[0].length();
boolean[][] isFilled = new boolean[nRow][nCol]; // 蜘蛛でそのセルが埋まっているかを記録
for( int i=0 ; i<A.length ; i++ ){
for( int j=0 ; j<A[0].length() ; j++ ){
int xpos = i; // 蜘蛛の位置
int ypos = j;
if( A[i].charAt(j) == 'N' ){ // セルの内容に応じて蜘蛛を動かす
xpos--;
}else if( A[i].charAt(j) == 'S' ){
xpos++;
}else if( A[i].charAt(j) == 'E' ){
ypos++;
}else{ // West
ypos--;
}
if( xpos < 0 || xpos >= nRow || ypos < 0 || ypos >= nCol ) continue; // 床に落ちる
isFilled[xpos][ypos] = true; // 動いた先の座標をtrueに変える
}
}
int nFilled = 0;
for( int i=0 ; i<A.length ; i++ ){
for( int j=0 ; j<A[0].length() ; j++ ){
if( isFilled[i][j] == true ) nFilled++;
}
}
return nRow*nCol-nFilled; // 空セルは全体から埋まっているセル数を引く
}
}
得点は183.69/250、2回目のsubmitでシステムテストクリア。breakとcontinueを間違える凡ミスをした。
2013年1月24日木曜日
TopCoder SRM456 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
アップルワードというのは、A、P、L、Eの文字のみからなり、ちょうどその順になっている単語をいう。Aは1つ、Pは2つ以上、LとEは1つである。大文字か小文字かは問題でない。例えば"apPpPPlE"はアップルワードであり、"ABCDE"はそうではない。wordというアップルワードに変えなければならない文字列型変数が与えられたとき、アップルワードに変換するのに最小限変換しなければならない文字数を返せ。もし変換できないのであれば、-1を返すようにせよ。
私の解答はこちら。
public class AppleWord {
public int minRep(String word) {
int len = word.length();
if( len < 5 ) return -1;
int nReplace = 0;
if( word.charAt(0) != 'A' && word.charAt(0) != 'a' ) nReplace++;
if( word.charAt(len-2) != 'L' && word.charAt(len-2) != 'l' ) nReplace++;
if( word.charAt(len-1) != 'E' && word.charAt(len-1) != 'e' ) nReplace++;
for( int i=1 ; i<len-2 ; i++ ){
if( word.charAt(i) != 'P' && word.charAt(i) != 'p' ) nReplace++;
}
return nReplace;
}
}
得点は222.52/250、1回のsubmitでシステムテストクリア。変換できない状況は、wordの長さが4以下のときとなる。
2013年1月23日水曜日
Rによる統計解析ハンドブック 第3章演習問題解答
This post is solutions of chapter 3 of `A Handbook of Statistical Analyses Using R, Second Edition'.
このポストはRによる統計解析ハンドブック(第2版)の第3章の解答になります。
1
To decide which is superior, I chose wilcox.test as relative merit is decided by the absolute difference from 43 meters. t.test doesn't tell us which index is better estimator. conf.int in wilcox.test is needed to get estimated value which indicates the difference of rank. In below code execution printed value(=-3.1999...) shows that feet is superior than meter though null hypothesis couldn't rejected as p-value is slightly greater than 0.05.
どちらが優れているかを決めるため、wilcox.testを選んだ。というのも、優劣は43からの絶対誤差で決まるからである。t.testはどちらの指標が優れた推定量であるかを示してはくれない。wilcox.testのconf.intは順位の違いを示す推定値を得るために必要である。p値が0.05よりわずかに大きいため帰無仮説(2群は順位差がない)は棄却できないものの、実行時に表示される値はfeetがmeterよりも優れていることを示している。
data("roomwidth", package="HSAUR2")
convert <- ifelse(roomwidth$unit == "feet", 1, 3.28)
wt <- wilcox.test(I(abs(width*convert-43))~unit, data=roomwidth, conf.int=TRUE)
print(wt$estimate) # =-3.200
2
data("water", package="HSAUR2")
by(water, water$location, function(x){ return(cor(x$mortality, x$hardness))})
3
There is a mistake in the textbook written in Japanese. The numerator of formula in the question should be (njk-Ejk)/sqrt(Ejk). Otherwise it can't take a nagative value.
日本語版テキストの公式は間違いで、分子の方は(njk-Ejk)/sqrt(Ejk)が正しい。そうしないと(N(0, 1)の分布なのに)負の値がとれないよね~
data("pistonrings", package="HSAUR2")
calc.res <- function(x){
sta.res <- chisq.test(x)$residuals
x.exp <- outer(rowSums(x), colSums(x))/sum(x) # creates Ejk
rr <- rowSums(x)
cc <- colSums(x)
nn <- sum(x)
adj.res <- matrix(nrow=nrow(x), ncol=ncol(x))
for( j in 1:nrow(x) ){
for( k in 1:ncol(x) ){
adj.res[j,k] <- (x[j,k]-x.exp[j,k])/sqrt(x.exp[j,k])/sqrt((1-rr[j]/nn)*(1-cc[k]/nn))
}
}
adj.res <- as.data.frame(adj.res)
rownames(adj.res) <- rownames(x)
colnames(adj.res) <- colnames(x)
return(list("sta.res"=sta.res, "adj.res"=adj.res))
}
pis.res <- calc.res(pistonrings)
4
The result of prop.test indicates that null hypothesis couldn't be rejected because p-value is greater than 0.05.
prop.testの結果はp値が0.05より大きいことから、(比率が一定という)帰無仮説が棄却できないことを示している。
data("rearrests", package="HSAUR2")
prop.test(rearrests, correct=FALSE)
2013年1月22日火曜日
TopCoder SRM454 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
整数の桁の和は10進数で書かれた桁の和である。例えば1234は1+2+3+4=10になる。さて、A、B、Cという3つの整数が与えられる。AとBの間にあるXという整数で、Xの桁の和とCの桁の和の差の絶対値が最小になるものを返せ。もし複数のXがあり得るなら、その中で最小のものを返せ。
私の解答はこちら。
public class MinimalDifference {
public int findNumber(int A, int B, int C) {
int target = digit_sum(C);
int diff = Integer.MAX_VALUE;
int ans = A;
for( int i=A ; i<=B ; i++ ){
int currentDiff = Math.abs(target - digit_sum(i)); // 差の絶対値の計算
if( currentDiff < diff ){ // Xの更新作業
diff = currentDiff;
ans = i;
}
}
return ans;
}
private int digit_sum(int num){ // 桁の和を計算する関数
// while文で0になるまで10で割った余りを足し、10で割ることを繰り返す方法もある
String snum = "" + num;
int s = 0;
for( int i=0 ; i<snum.length() ; i++ ){
s += snum.charAt(i) - '0';
}
return s;
}
}
得点は235.47/250、1回のsubmitでシステムテストクリア。Xの更新作業では、複数の候補から最小値を返すので、<=としないように注意。
2013年1月20日日曜日
TopCoder SRM453.5 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
あなたは大工さんで、家具をいくつか作りたいと思っている。不幸なことに、すべての道具を無くしてしまった。need[]という、i番目の要素は、スペースで区切られた家具を作るのに必要な道具のリストが与えられる。すべての家具を作るのに買わなければならない異なる道具の数を返せ。
私の解答はこちら。
import java.util.HashSet;
public class ToolsBox {
public int countTools(String[] need) {
HashSet<String> hs = new HashSet<String>();
for( int i=0 ; i<need.length ; i++ ){
String[] tools = need[i].split(" "); // スペース区切りのリスト
for( int j=0 ; j<tools.length ; j++ ){
hs.add(tools[j]); // ハッシュに放り込む
}
}
return hs.size(); // ハッシュのサイズ=買わなければならない道具の数
}
}
得点は246.90/250、1回のsubmitでシステムテストクリア。
2013年1月16日水曜日
TopCoder SRM453 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
ジョンとブラスはチームスポーツのトーナメントに興味を持っている。彼らは現在のトーナメントの中間順位を調べている。これまでにどの試合が行われたかについては知らない。彼らはトーナメントが以下のルールに基づいて行われたことだけを知っている: 各ゲームは2チームで行われ、一方の勝利または引き分けの結果になる。もしあるチームが試合に勝つと、2ポイントを得て、相手は0ポイントを得る。引き分けの場合には、各チームに1ポイントずつ入る。チームの得点は試合から得たポイントの総和である。どのチームとやりあうかということについての制限はなく、各チームの組で何試合してもよい(0の可能性もある)。
points[]というトーナメントの中間順位を表す整数型の配列が与えられる。i番目の要素はチームiの得点を表す。この順位を作成するのに必要となる試合の最小数を返せ。もしpointsが妥当な状態を表していないのであれば、-1を返すようにせよ。
私の解答はこちら。
public class TheTournamentDivTwo {
public int find(int[] points) {
int sum = 0;
for( int i=0 ; i<points.length ; i++ ){
sum += points[i];
}
if( sum % 2 == 1 ) return -1;
return sum / 2;
}
}
得点は246.97、1回のsubmitでシステムテストクリア。-1になるのは、合計点が奇数のときだけである。これは、1試合するたびに合計2点が2チームに入るためである。最小の試合数は合計点/2でよい。
2013年1月15日火曜日
Rによる統計解析ハンドブック 第2章演習問題解答
This post is solutions of chapter 2 of `A Handbook of Statistical Analyses Using R, Second Edition'. Note that my interpretations of data may differ from yours, but they are not the only solutions.
このポストはRによる統計解析ハンドブック(第2版)の第2章の解答になります。私のデータの解釈はあなたのそれらとは異なるかも知れませんが、唯一の解答ではないことに注意してください。
1
I aggregated expenditure for each gender. Compared to men, women tend to spend much money on housing and less on food.
性別ごとに支出金額を集計した。男性と比較して、女性は住まいへの費用が多く、食費への支出が少ない傾向にある。
lst <- split(household, household$gender)
expenses <- sapply(lst, function(x){colSums(x[,1:4])})
normalize <- matrix(rep(colSums(expenses),4), ncol=2, byrow=T)
ratios <- expenses/normalize
xpos <- barplot(ratios)
ypos <- diff(rbind( c(0, 0), apply(ratios, 2, cumsum)))/2 +
rbind( c(0, 0), apply(ratios, 2, cumsum))[1:4,] # calculate y coord to insert strings
text(rep(xpos, each=4), ypos, rep(rownames(ratios), 2))
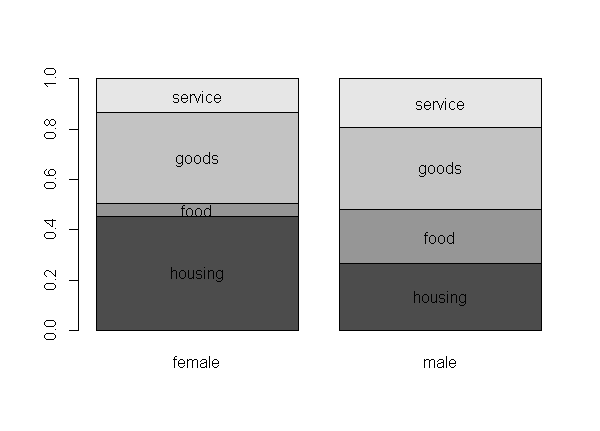
2
As men get older, suicide rate increases. All of outliers belong to Hungary. Assume that library(HSAUR2) is already done. If not, execute data("suicides2", package="HSUAR2").
年齢が上がるに連れて自殺率が上がる。外れ値はいずれもハンガリーになっている。library(HSAUR2)は実行済みと仮定してください。もししていなければ、data("suicides2", package="HSUAR2")を実行するように。
boxplot(suicides2)
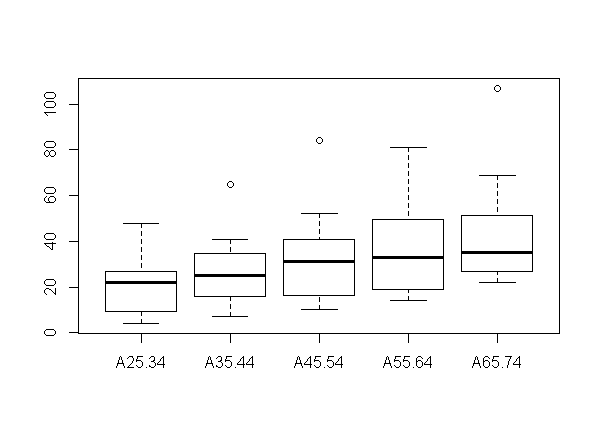
3
This answer shows how to change points into strings when using function pairs. By controlling parameter `panel', we can control both lower.panel and upper.panel. In case of changing counterpart, we should define functions for each panel. q2 required me to plot Life.Expectancy - Homicide relationship conditioned by Income, but no indication about it in text book. So I divided data whether it is higher or lower than the median income.
対散布図で描画するときに、点を文字に変えるにはどうしたら良いかという解答がこれになります。panelを制御することで、lower.panelとupper.panelを両方とも制御することができます。一方だけ変えたい場合は、それぞれに対して関数を定義してやる必要があります。q2では、平均収入を条件とした平均余命と殺人率のプロットを描くのですが、平均収入を条件とするということに関する指示がありません。ここでは、収入が中央値より高いか低いかでデータを分けました。
# states.abb <- abbreviate(rownames(USstates), minlength=2)
# q1
states.abb <- c("AL", "CA", "IA", "MS", "NH", "OH", "OR", "PA", "SD", "VT")
pairs(USstates, panel=function(x, y, ...){ text(x, y, states.abb) })
# q2
cond <- ifelse(USstates$Income < median(USstates$Income), "Lower", "Upper")
xyplot(Life.Expectancy ~ Homicide | cond, data=USstates)


4
When I used pairs, I found counterfeits were slightly short in diagonal length. To confirm that, I used boxplot.
対散布図を使ったところ、偽物がわずかに対角線の長さが短いことに気づきました。それを確認するために、箱ひげ図を利用してみました。
data("banknote", package="alr3")
pairs(banknote, col=banknote$Y+1) # black=genine, red=fake
boxplot(banknote$Diagonal~banknote$Y)


2013年1月11日金曜日
Rによる統計解析ハンドブック 第1章演習問題解答
This post is solutions of chapter 1 of `A Handbook of Statistical Analyses Using R, Second Edition'. As far as I know, there's no solutions on Web, so I decided to post my answers and hope to sophiscate them through discussing if needed.
このポストはRによる統計解析ハンドブック(第2版)の第1章の解答になります。私の知る限り、解法はWeb上にありませんので、私の解答を掲載することを決心しました。必要があれば議論して解答をより良くしたいと思っています。
Because almost no contents in the text book is written in this post, so please get one previously.
テキストに書かれている内容はほぼこのポストにありませんので、本は予め入手しておいてください。
1
library(HSAUR2)
prof.meds <- tapply(Forbes2000$profits, Forbes2000$country, median, na.rm=T)
print(prof.meds[c("United States", "United Kingdom", "France", "Germany")])
In the following answers, assume that `library(HSAUR2)' is already executed.
以後library(HSAUR2)は既に実行されていることを仮定せよ。
2
ger.deficit <- Forbes2000$country == "Germany" & Forbes2000$profits < 0 print(Forbes2000[ger.deficit, ])
3
Insurance Company is majority of this data (bermuda).
bermuda <- Forbes2000$country == "Bermuda" print(table(Forbes2000[bermuda, "category"]))
4
big.profit <- Forbes2000[Forbes2000$profits >= sort(Forbes2000$profits, dec=T)[50],] big.profit <- big.profit[!is.na(big.profit$profits),] plot(big.profit$assets, big.profit$sales, log="xy", type="n") text(big.profit$assets, big.profit$sales, abbreviate(big.profit$country))
5
print(tapply(Forbes2000$profits, Forbes2000$country, mean, na.rm=T))
larger <- function(x, th){
return(length(which(x > th)))
}
print(tapply(Forbes2000$profits, Forbes2000$country, larger, 5))
2013年1月9日水曜日
TopCoder SRM452 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
2種類の卵のカートンがある。1つは6つの卵を、もう1つは8つの卵を含んでいる。ジョンはちょうどn個の卵を買いたいと思っている。ジョンが買わなければならない最小のカートンの数を返せ。もしちょうどn個の卵を買うことができないのであれば、-1とせよ。
私の解答はこちら。
public class EggCartons {
public int minCartons(int n) {
int nCarton = 0;
if( n % 2 != 0 ) return -1;
if( n == 2 || n == 4 || n == 10 ) return -1;
return (int)Math.ceil(n / 8.0);
}
}
得点は137.04/250、2回目のsubmitでシステムテストクリア。紙に書いて規則性を見つけるのが一番早いかと。
2013年1月8日火曜日
TopCoder SRM451 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
リックは固くいくつかの数字に関係する魔法のパターンがあると信じている。この信念はそこらじゅうで奇妙なパターンを見つける彼の傾向の結果である。リックは最近いくつかの数字に"魔法の源"があると考えた。例えば、1370974という数字は、以下の手順により、1234に等しい魔法の源を持つ。これは1234+12340+123400+1234000=1370974という計算ができることによる。n個の数字の数列で、i番目の数字が1234に10^iをかけたものの総和が1370974になるものがあることから、公式に1234は1370974の魔法の源である。この定義により、正の整数はそれ自身の魔法の源でもあることに注意。さて、sourceとAという正の整数が与えられたとき、Aより大きく、sourceがxの魔法の源となるような最小の数を返せ。
私の解答はこちら。
public class ReverseMagicalSource {
public int find(int source, int A) {
int num = source;
int i = 1;
while( true ){
if( num > A ) break;
num += source * Math.pow(10, i);
i++;
}
return num;
}
}
特に注意点はなし。言われた通りに書くだけですね。強いて言うなら、最小の数を判定するときに、Aより大きくの場所でうっかり=をつけないぐらいですが...
2013年1月6日日曜日
TopCoder SRM450 Div2 250Pts
このTopCoderの問題はこちらで見ることができる(要TopCoder登録 & 問題文は英語)。問題文についておおまかに説明する。
あなたはとてもおかしなコンピュータを与えられた。コンピュータのメモリはいくつかのビットからなり、それぞれは0で初期化されており、以下の操作の種類のみ振る舞うことができる:メモリのあるビットを選び、0か1の値を選択する。メモリの選択されたビットと最後のビットの間のすべてを選んだ値にする。さて、memという文字列が与えられる。memの文字の数はコンピュータのメモリの数に等しい。コンピュータのメモリをmemと同じにするのに必要となる最小の操作の回数を返すメソッドを作成せよ。
私の解答はこちら。
public class StrangeComputer {
public int setMemory(String mem) {
int nChange = 0;
char bit = '0';
for( int i=0 ; i<mem.length() ; i++ ){
char c = mem.charAt(i);
if( bit != c ){
nChange++;
bit = c;
}
}
return nChange;
}
}
この問題では先頭から順に直前の文字と比較して、0と1が反転した回数を数えればよいことになる。先頭の文字の前の文字はすべて0に初期化するという条件から、0と考えておけばよい。
2013年1月5日土曜日
2012年12月の学習記録
2012年12月に学習した主な本一覧。忘年会を何回やったことでしょうか。
- 入門・演習 数理統計(演習問題39問)
- いよいよ最終章。来月で終わりそうな感じです。そろそろ昔解けなかった問題に挑戦するときかも。
- カウントデータの統計解析(pp.112~152)
- テキストにところどころ出てくる反復解法の妥当性がいまだによく分かりません。どういうときに収束することが保証できるんですかね。それとテキストやWebで公開されている解答にタイポが3ヶ所ぐらいありました。
- JavaScriptワークブック(pp.120~159読了)
- Webのテーブルや画像はすべてオブジェクトなので、それをどういじるのかということを学んだ。ただしjQueryとかライブラリには立ち入ってないので、ここでは概要のみ学んだ感じ。
- Pythonスタートブック(読了)
- 復習を兼ねて読んでみたが、オライリーと「みんPy」の本で十分そうだ。
- Beautiful Visualization(pp.1~25)
- インフォグラフィックスの一例を学ぶ。アメリカ大統領の選挙で政党が獲得した州はそのままのサイズでなく、州の議員数に比例したサイズで地図を書くと情報量が増えるとか。
- 初めてのLISP(pp.1~32)
- carやcdrとは何かということが最初の32ページに載っていて、初めて知りました。奥が深そうなので、あまり手を突っ込み過ぎたくはないのですが、SICPなんかを将来的に読もうとしているので、遅かれ早かれ手を出さないといけない感じですね。
その他、TopCoderの過去問を約15問解く。英文ドキュメント翻訳の作業は約40%まで到達。今年度中には何とかリリースできそうか...?
登録:
投稿 (Atom)